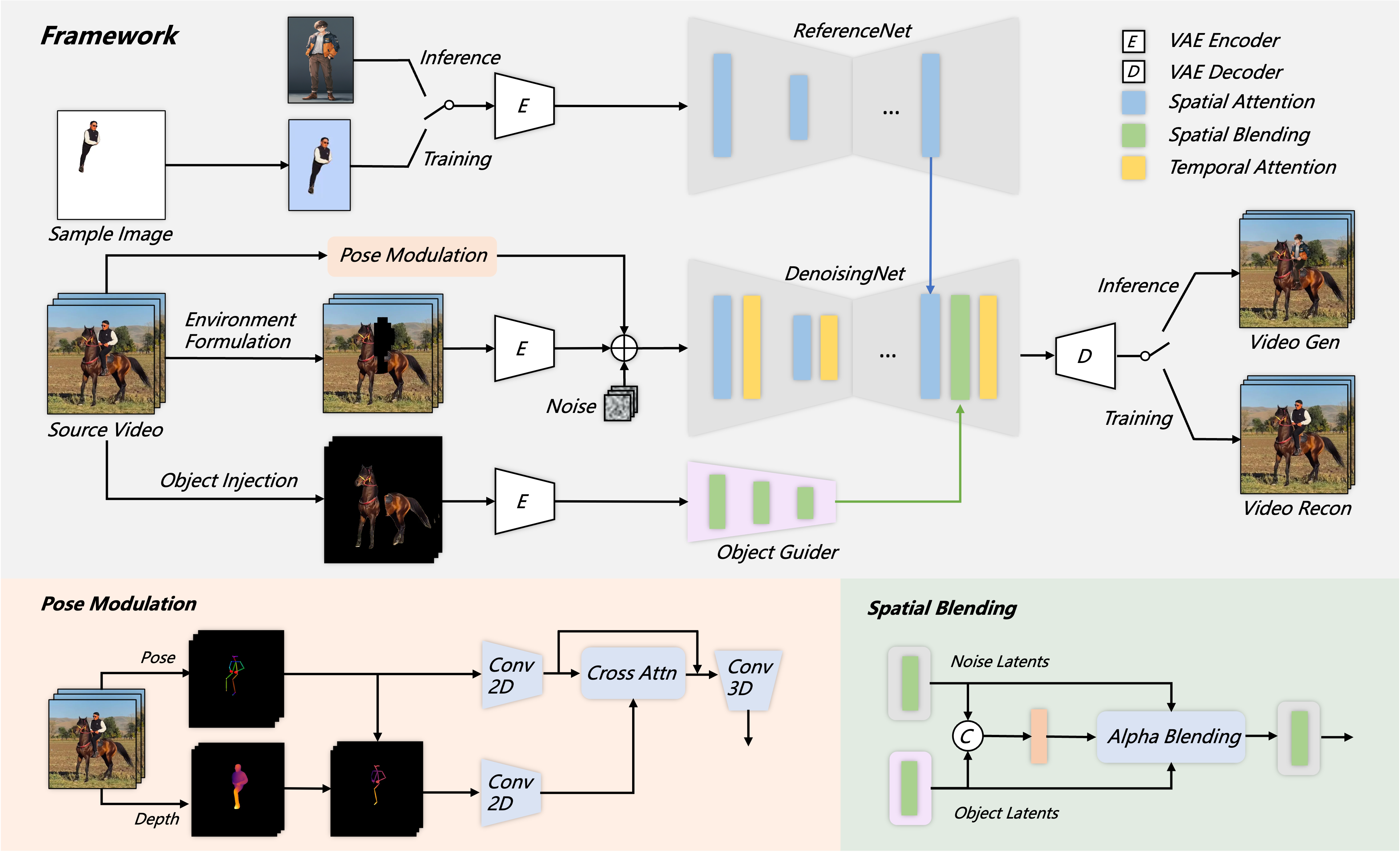
Motivation

We propose Animate Anyone 2, which differs from previous character image animation methods that solely utilize motion signals to animate characters. Our approach additionally extracts environmental representations from the driving video, thereby enabling character animation to exhibit environment affordance.